Why Project Hadron?
Project Hadron provides robust, reusable Machine Learning pipelines for a preprocessing and model predict lifecycle, run as a single or multiple microservices within an application solution. It also lends itself to exploratory data analysis (EDA) integrating with existing data science packages and processes.
Project Hadron provides a light weight, quick-to-market, machine learning framework, sitting on apache arrow, to considerably increase productivity, performance and integration of reusable pipelines towards production objectives.
What are we solving?
The 80/20 rule, also known as the Pareto Principle, is a concept widely used in various fields, including data engineering and data science to denote the imbalance between effort and purpose.
In the context of data engineering, the 80/20 rule suggests that approximately 80% of the effects or outcomes come from 20% of the causes or inputs, such as data veracity, software governance and solution reuse. While with data scientists, the 80/20 rule suggests that approximately 80% of time is spent finding, cleaning, and extracting features of interest with only 20% to perform data analytics initiatives. In addition Gartner suggests, 85% of data science initiatives fail because they don’t deliver business benefits because they solve the wrong problem.
Further more research shows 62% of data processing pipelines depend on others within their organization to perform certain steps, within stringent deadlines, in a data processing pipeline. Yet poor communication and limited visibility between data scientists, data engineers and business stakeholders directly effects success of business objectives.
Where does Project Hadron fit?
Project Hadron is an open-source application framework, taking raw data and identifying, analysing and extracting prepared data along with the management of ML trained models and their prediction for the purposes of a down stream business objective.
Project Hadron is a comprehensive set of tools to build, improved, optimise features of interest and auto run predictions within a data preprocessing pipeline. It complements and enhances both communication and redistribution within a data science project, while providing clear boundaries between the preprocessing of data and algorythm optimisation. This separation promotes transparency and reuse, vastly improving the identification and extraction of features of interest.
Project Hadron, within a data processing step, executing business driven analysis, is a quick-to-market, robust set of tools that build reusable pipelines for the interrogation and restructure of data for a target use case. It helps in identifying potential failures at the earliest stage and helps ensure a transparent and traceable data foundations for success. It handles large data through memory efficiency, facilitates interoperability and optimisation of CPU and GPU acceleration.
Project Hadron has been built to help bridge the gap between data scientists, data engineers and business stakeholders with a comprehensive set of reporting tools covering data profiling, data lineage and knowledge acquisition. Its targeted reports can be directly delivered as spreadsheets for stakeholders, absorbed into an already existing reporting tool for analytics or saved in cloud storage all saved in parquet files for interoperability with other solutions.
Within the context of data processing, Project Hadron offers data governance optimization, data quality consistency, data efficiency improvement and risk of error reduction.
What are its design methodologies?
Project hadron is an open-source application framework, written in pure Python using PyArrow as its canonical and depends on a few key Python packages found in any analytics environment such as Pandas and Numpy.
Project Hadron was constructed using object-oriented design (OOD) and object-oriented programming (OOP) techniques to provide an extendable framework for quick build component solutions. When used together, Pandas and PyArrow form a powerful combination for handling diverse data processing tasks efficiently.
It is designed to be used as a development and discovery toolset or a set of Microservices within a data processing pipeline, with each Microservice having its own pipeline of capabilities. Each capability, and thus pipeline, has its own reporting methods providing transparency and traceability.
Where does it sit within a system pipeline?
Project Hadron provides a set of capabilities fundamental to the optimisation and appropriateness of tabular data for a downstream business objective. As such it places itself as a machine learning preprocessing and model processing step, though its application can be applied far wider.
When applied to preprocessing for data science and machine learning, the scope of reference is to data selection, feature engineering, feature build and feature transformation as steps to clean, create, format, and organize source data into a suitable format for the process of model evaluation and tuning. FeaturePredict manages trained model classes and runs ML model predict. The following diagram illustrates where preprocessing sits within the machine learning pipeline.

This same process exists in ‘The Three Stages of Data Processing’, where the architecture consists of three essential elements: a source or sources, processing steps, and a destination. Similar to the machine learning preprocessing and taken from its references, these steps include transformation, augmentation, filtering, grouping, and aggregation. The following diagram illustrates where the processing sits within the three stage pipeline pipeline.
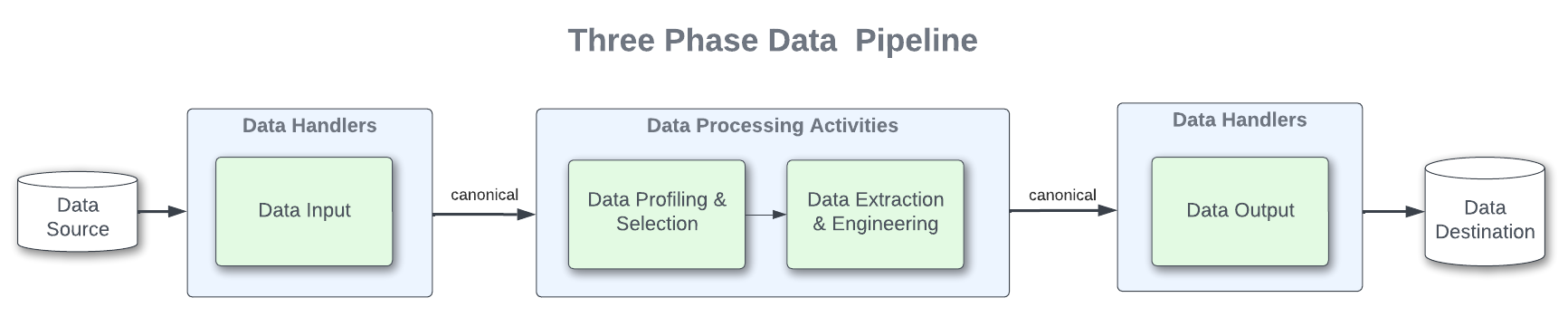
What are capabilities?
In project Hadron capabilities are components that adhere to the fundamental concepts of capability patterns and separation of concern (SoC). They are design principle that advocates breaking a software system into distinct, independent modules or components with, low coupling and high cohesion each addressing a specific concern or aspect of the system’s functionality.
Capabilities are reusable and encapsulated tasks which can be applied at any stage of the life cycle and prescribes a work breakdown structure of functionalities and features a software solution possesses.
Within Project Hadron these capabilities can be identified as:
data selection
feature engineering for creation
feature engineering for correlation
feature engineering for modelling
feature transition
feature predict
Together, capability patterns help in understanding what a reusable component task should achieve, while separation of concerns ensures that the component task is designed in a modular and maintainable way, with each part addressing a specific aspect of its functionality. Both principles contribute to building modular, robust and scalable software solutions.
How are capabilities reusable?
While using the actions of a capability, those actions, and other metadata, are recorded as a runbook of instruction of the lineage of that instance. This runbook is known as a capability recipe that contain all information relating to a capability, capturing the state of a capability at that moment in time. By referencing a capability by name at initialization you load the receipt from its previous state, which can be modified, enhanced or re-run.
What is a capability pipeline?
A capability does not relate to any specific part of a lifecycle, only to the task it has been designed, FeatureSelect for dimensionality, FeaturePredict for model predict, etc. It is designed in a way that it is applicable to any related a use case, thereby enabling its activities to be flexibly assigned to a delivery process to which it is being applied.
Capabilities, on their own, are tightly focused on their concerns, albeit with a use case in mind. It is not till we collectively link our capabilities in a meaningful order that we build our reusable use case or microservice. In order to capture a set of capabilities into a reusable microservice, Project Hadron creates a pipeline of these components, their connectivity, their actions and encapsulates how they should run.
In order to be able to run a capability pipeline as a cohesive microservice, a specialist capability, called a Controller, coordinates the running order of each recipe, that form the microservice. This controller also has its own recipe and collectively is known as a capability pipeline
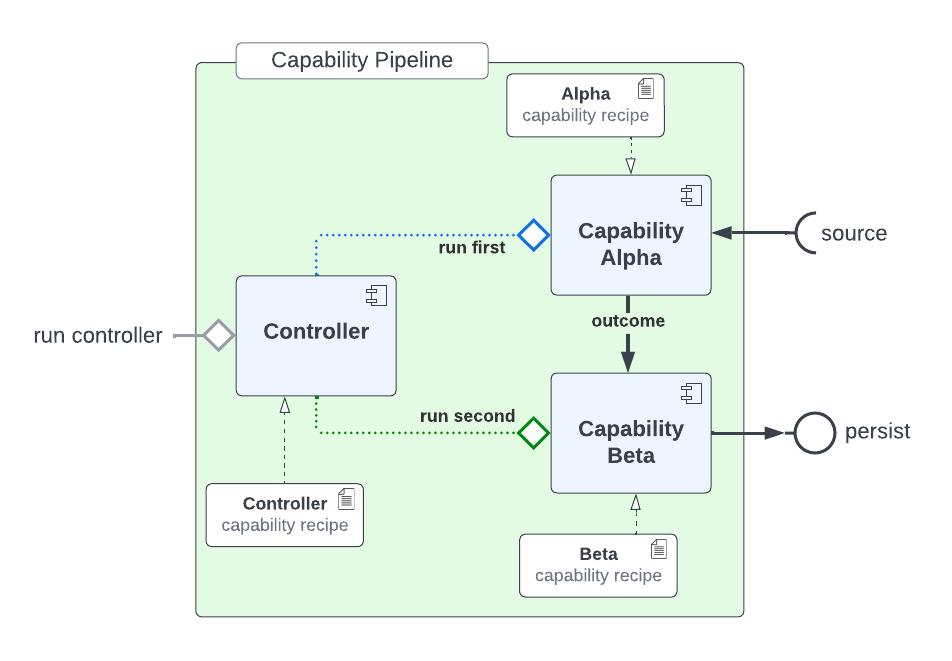
From the diagram you can see the encapsulated microservice within which the Hadron capabilities exists and the recipes that make up the reusable capability pipeline. This means that capability recipes can go from simple input output microservices to more complex and dependent solution applications.
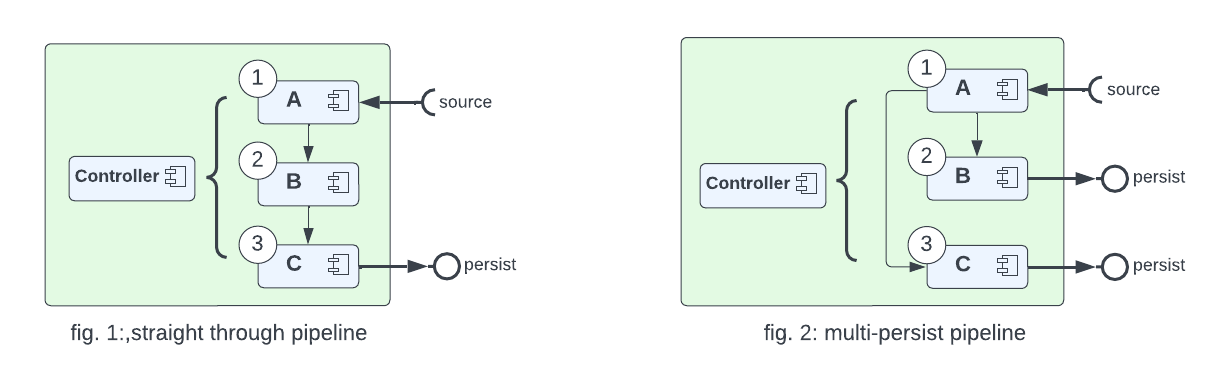
fig. 1 Shows a straight through process with one source and one output and three capability components.
fig. 2 maintains a single source but in this case each capability has its own output.
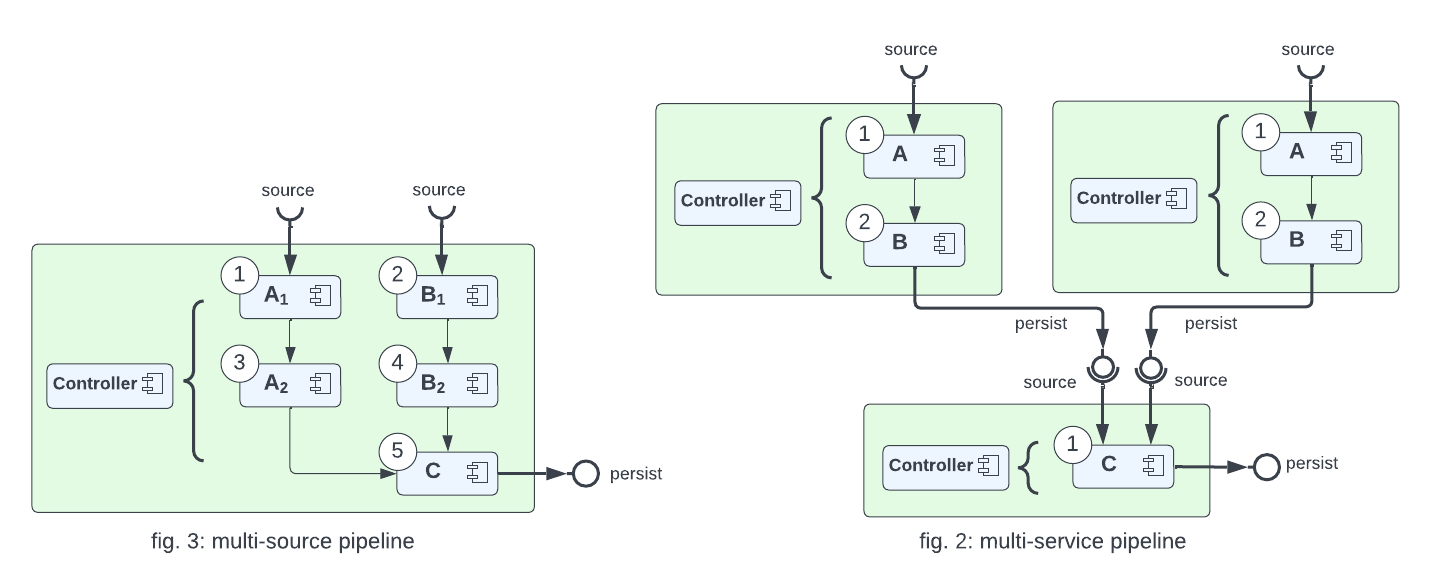
fig. 3 shows a more complex multi input with five components and two merging pipelines being encapsulated within a single microservice,
fig. 4, while still providing the same complex input output, has been separated into three microservices with the responsibility of managing the pipeline with the environment system.
This allows the designer and implementer to choose the best way to manage and monitor a set of capability recipes into a meaningful business objective.
Where can Project Hadron be applied?
Project Hadron can run as (1) a complementary functional toolkit in Jupyter Notebooks for Data Scientists, (2) an object oriented collection of abstract and concrete classes for building software solutions in PyCharm or Visual Studio, (3) or an implementation of a script image into a Docker environment or as a collection of Microservices in a cloud-native architecture.
Written in pure Python and depends on only a few well-established and supported Python packages, Project Hadron’s quick-to-market design lends itself pilots and with extensive interoperability, POCs. Its robustness and reuse along with its implementation as microservices place it in any larger project for data analytics and data processing.
Who would use Project Hadron?
As a Data Scientist. Project Hadron requires a knowledge of Python 3.8+, PyArrow, Pandas, Numpy as a core with a skilled blend of domain expertise, inference and the ability to adopt alternative systems to improve project sharing and feature identification. An understanding of Jupyter Notebooks or Jupyter Lab.
As a software developer, Project Hadron requires a knowledge of Python 3.8+ and PyArrow. A good understanding of some sort of Python interface, or Python IDE such as PyCharm or Visual Studio or as Jupyter Notebooks. Data selection, feature engineering and feature transition are the most essential part of Hadron, building a usable data pipeline and involves a skilled blend of domain expertise, intuition and lateral thought.
As an implementer, Project Hadron capability recipes, the skill set depends very much on the environment the pipeline is being implemented into. For example if you are implementing Hadron pipelines into a Docker environment there are no code requirements from Hadron as it is presented as a Docker image and the parameters around that. This will be the same for most implementations, brad there is no or low code input.
What is PyArrow?
PyArrow is the Python implementation of Apache Arrow, which is an open-source, cross-language development platform for in-memory data. Apache Arrow defines a standardized language-independent columnar memory format that facilitates efficient data interchange between different systems and programming languages. Project Hadron uses the power of Pandas for data manipulation and PyArrow as its in-memory canonical carefully considering PyArrow in its design to negate the challenges associated with Pandas.
Pandas stands out for its intuitive columnar data structure, ease of use, extensive functionality, and strong community support, making it a preferred choice for data analysts and scientists working with structured data in Python. But Pandas is rightly challenged for high memory consumption, slow performance and limitations in handling large datasets. PyArrow, when used as a complementary package, provides solutions to these issues.
PyArrow provides an in-memory columnar data representation that is more memory-efficient than Pandas DataFrames, alleviating the memory burden associated with large datasets. Additionally, PyArrow enhances interoperability, allowing seamless data interchange between Pandas and other systems through its support for Apache Arrow-based formats. The adoption of the Apache Parquet file format by PyArrow contributes to improved I/O performance and reduced storage requirements when reading and writing data. PyArrow also supports parallel and distributed computing, addressing Pandas’ limitations in handling big data and enabling users to scale their computations across clusters. The consistency in data types enforced by PyArrow contributes to enhanced data integrity, and efficient Arrow-based operations provide performance boost.
Integrating PyArrow with Pandas allows users to leverage these advantages, making their data manipulation and analysis workflows more efficient and scalable.
For more information visit Apache Arrow
Quick glance features
Capabilities
Data Selection
Feature Creation
Feature Transformers
Time series
Knowledge Augmentation
ML Model Management
ML Prediction
Performance
Apache PyArrow Canonical
improved memory management
large Data Processing
Interoperability
MicroServices
Reuse
Data Reporting
Data Lineage
Data Profiling
Knowledge Acquisition